Auto encoder
- 데이터의 효율적인 표현을 학습하는 인공 신경망 모델
- 데이터의 중요한 특성을 추출 -> 압축 -> 복원
- 오토인코더는 원본 데이터를 제한된 크기의 잠재 공간을 사용하여 최대한 근접하게 생성해내는 학습을 하는 과정에서 원본데이터가 갖는 중요한 특성을 잡아냄

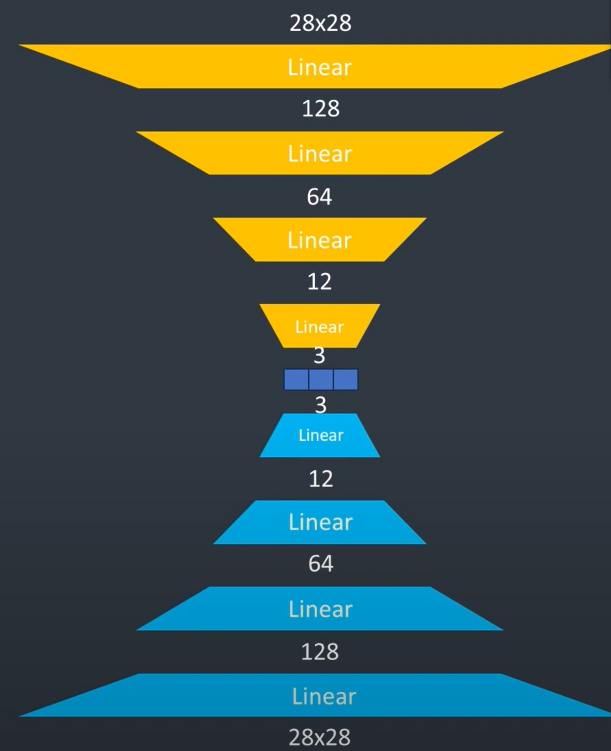
- 구성: Encoder / 잠재공간(latent space, coding) / Decoder
- Latent space
- 차원축소(dimension reduction)를 함 (데이터의 특성을 줄이는 과정)
- 이는 계산 효율성을 높이고 노이즈를 줄이며, 데이터를 잘 이해하기위해 사용
- e.g. 불필요한 정보를 제거하고 중요한 정보를 유지함으로써 모델의 성능을 개선
- 입력값의 핵심특성을 표현하는 압축된 형태의 피처맵을 형
- 활용
- 중요특성 학습
- 이미지 노이즈제거
- 데이터복원
PyTorch based Auto encoder
- MNIST 데이터셋을 이용한 Auto encoder
- 28*28 (2D 행렬) 데이터를 받아서 784(3D)차원 데이터로 출력
코드 실습
# 필요한 libarary 불러오기
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
import ipywidgets as widgets
from IPython.display import display
import os
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# Encoder
self.encoder = nn.Sequential(
nn.Linear(28*28, 128), #784를 128로 줄이고 # Linear: 차원을 줄여주는 역할
nn.Tanh(),
nn.Linear(128, 64), # 128을 64로 줄이고
nn.Tanh(),
nn.Linear(64, 12), # 64를 12로 줄이고
nn.Tanh(),
nn.Linear(12, 3) # 잠재공간 # 3차원공간으로 줄임 (높을수록 복원률이 좋음)
)
# Decoder
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.Tanh(),
nn.Linear(12, 64),
nn.Tanh(),
nn.Linear(64, 128),
nn.Tanh(),
nn.Linear(128, 28*28),
nn.Sigmoid() # Output a value between 0 and 1
)
# 순전파
def forward(self, x):
x_encoded = self.encoder(x)
x = self.decoder(x_encoded)
return x, x_encoded
# 데이터 변환
transform = transforms.Compose([
transforms.ToTensor(), # Tensor로 변환
transforms.Normalize((0.5,), (0.5,))
])
# 학습 데이터 로드
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True) # 32씩 #shuffle: 랜덤으로 섞어서 보겠다
# 테스트 데이터 로드
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transforms.ToTensor())
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=True) # Larger batch size for testing
# 모델 초기화, 손실함수, 옵티마이저
model = Autoencoder() #모델 생성
criterion = nn.MSELoss() # mse를 쓰겠다
optimizer = optim.Adam(model.parameters(), lr=1e-3) # 역전파로 구한 가중치들의 변화를 업데이트해주는 역할
#학습
num_epochs = 20
for epoch in range(num_epochs):
for data in train_loader: # 각각의 데이터를 불러내서
img, _ = data
img = img.view(img.size(0), -1) # Flatten the images # 1차원 행렬로(길이가 784개)로 바꿔주고
output,_ = model(img) # 오토인코더에 넣어서 최종 output 구함
loss = criterion(output, img) # mse로 손실을 구함
optimizer.zero_grad()
loss.backward() # 손실을 사용하여 역전파 구함
optimizer.step() # 각각의 가중치를 업데이트
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
print("Training Complete")
# 테스트
dataiter = iter(test_loader)
images, _ = next(dataiter)
images_flattened = images.view(images.size(0), -1) # 테스트 데이터도 748로 바꿔줌
# 테이스 이미지 순전파
output, _ = model(images_flattened)
output = output.view(output.size(0), 1, 28, 28).detach() # 눈으로 확인하기위해 실제 이미지 형태로 변환
# 테스트 이미지 결과 시각화
fig, axes = plt.subplots(nrows=2, ncols=10, sharex=True, sharey=True, figsize=(20,4))
# Original images와 비교
for images, row in zip([images, output], axes):
for img, ax in zip(images, row):
ax.imshow(img.squeeze().numpy(), cmap='gray')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
- Encoder/ Decoder 구조가 대칭으로 되어있음
'TIL(2024y) > Deep learning' 카테고리의 다른 글
| 24.07.29 CNN 2 (0) | 2024.07.29 |
|---|---|
| 24.07.04-05 RNN (0) | 2024.07.08 |
| 24.07.03 CNN (0) | 2024.07.06 |
| 24.07.01 Deep learning (구조 및 역할) (0) | 2024.07.01 |
| 24.06.12 Review(Decision Tree/ Random Tree) (1) | 2024.06.12 |



