Deep Learning Algorithms
- CNN(Convolutional Neural Network)
- FNN
- RNN
CNN(Convolutional Neural Network)
- MNIST: 미국 국립표준기술원(NIST)에서 손글씨 숫자 이미지를 모아 만든 데이터셋 (손글씨를 컴퓨터가 알아보는 것)

- CNN
- 딥러닝보다 더 복잡하고 방대한 data를 다룰 때 사용하는 모델
- 일부 특징만 뽑아서 마지막 layer(fully connected layer)로 보냄(합성곱 계층을 사용하여 이미지에서 패턴을 추출)
- 이미지나 비디오 데이터 처리에 적합
- 전체 구조

- CNN을 사용하지 않으면
- 너무 많은 컴퓨터 자원 필요
- 과적합 발생
- Convolution(합성곱)
- 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 다음, 구간에 대해 적분하여 새로운 함수
실습
- 딥러닝
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import sys
# MNIST 데이터셋을 불러와 학습셋과 테스트셋으로 저장합니다.
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 학습셋과 테스트셋이 각각 몇 개의 이미지로 되어 있는지 확인합니다.
print("학습셋 이미지 수 : %d 개" % (X_train.shape[0]))
print("테스트셋 이미지 수 : %d 개" % (X_test.shape[0]))
# 첫 번째 이미지를 확인
plt.imshow(X_train[0], cmap='Greys')
plt.show()
# 이미지가 인식되는 원리
for x in X_train[0]: # x_train[0]의 각 요소x에 대해 반
for i in x: # x의 각 요소 i에 대해 반복
sys.stdout.write("%-3s" % i) # i를 최소 3자리 너비로 출력
sys.stdout.write('\n') # 줄바꿈 문자를 출력하여 다음 줄로 이동
- 손글씨 이미지를 컴퓨터는 이렇게 인식
- 이미지의 하얀색 바탕은 0으로 글씨가 있는 부분은 진할수록 255에 가까운 숫자로 인식
- 5라는 숫자가 2차원으로 가로*세로 28*28로 되어있는 구조인데, 이것을 1차원의 긴 데이터를 변형필요 (reshape)
# 차원 변환 과정을 실습X_train = X_train.reshape(X_train.shape[0], 784) # 2차원의 28*28 구조를 1차원의 784개 줄로 변형X_train = X_train.astype('float64') # 실수로 변형X_train = X_train / 255 # 나열한 0~255까지 너무 범위가 커서 0~1까지의 숫자로 변형 (정규화)
X_test = X_test.reshape(X_test.shape[0], 784).astype('float64') / 255 # 위의 코드를 x_test에 대해서 한줄로 쓴것
# 클래스 값을 확인print("class : %d " % (y_train[0])) # y_train의 첫번째 숫자를 확인 (5라고 나옴)
# 바이너리화 과정을 실습y_train = to_categorical(y_train, 10) # 0~9까지의 숫자를 one_hot encoding을 통해 0,1로 바꿔줌y_test = to_categorical(y_test, 10)
print(y_train[0])# 모델 구조를 설정합니다.model = Sequential() # sequential()을 이용해 층을 쌓겠다model.add(Dense(512, input_dim=784, activation='relu'))# 784개를 입력하고 중간 은닉층 노드수를 임의로 512개로 설정model.add(Dense(10, activation='softmax')) # 0~9개의 숫자중 1개를 선택 (다중 분류)model.summary()# 모델 실행 환경을 설정합니다.model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 최적화를 위한 설정 구간입니다.modelpath="./MNIST_MLP.hdf5"checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)# 10번이상 성능이 좋아지지 않으면 early stopping하고 저장하겠다.
# 모델을 실행합니다.history = model.fit(X_train, y_train, validation_split=0.25, epochs=30, batch_size=200, verbose=0, callbacks=[early_stopping_callback,checkpointer])
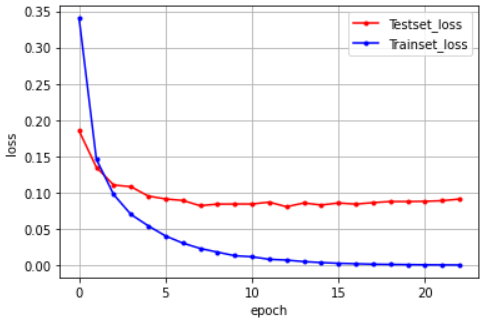
# 테스트 정확도를 출력합니다.print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1]))# 검증셋과 학습셋의 오차를 저장합니다.y_vloss = history.history['val_loss']y_loss = history.history['loss']
# 그래프로 표현해 봅니다.x_len = np.arange(len(y_loss))plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
# 그래프에 그리드를 주고 레이블을 표시해 보겠습니다.plt.legend(loc='upper right')plt.grid()plt.xlabel('epoch')plt.ylabel('loss')plt.show()
- CNN
from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2Dfrom tensorflow.keras.callbacks import ModelCheckpoint,EarlyStoppingfrom tensorflow.keras.datasets import mnistfrom tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as pltimport numpy as np
# 데이터를 불러옵니다.(X_train, y_train), (X_test, y_test) = mnist.load_data()X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 255y_train = to_categorical(y_train)y_test = to_categorical(y_test)
# 컨볼루션 신경망의 설정model = Sequential()model.add(Conv2D(32, kernel_size=(3, 3), input_shape=(28, 28, 1), activation='relu'))# 몇번반복할것인가: 32#2d 이미지라서 #(28, 28, 1) input 이 2차원 # 흑백이면 1 컬러면 3model.add(Conv2D(64, (3, 3), activation='relu'))model.add(MaxPooling2D(pool_size=(2,2)))# pooling이 2*2인 창을 만들어서 #max pooling: 그 중 가장 큰 값을 선택하라model.add(Dropout(0.25))# 전체를 다 쓰지않고 25%의 node를 꺼주고 나머지만 쓰라model.add(Flatten())# 2d를 1d로 변형model.add(Dense(128, activation='relu'))model.add(Dropout(0.5))model.add(Dense(10, activation='softmax'))
# 모델의 실행 옵션을 설정합니다.model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
# 모델 최적화를 위한 설정 구간입니다.modelpath="./MNIST_CNN.hdf5"checkpointer = ModelCheckpoint(filepath=modelpath, monitor='val_loss', verbose=1, save_best_only=True)early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
# 모델을 실행합니다.history = model.fit(X_train, y_train, validation_split=0.25, epochs=30, batch_size=200, verbose=0, callbacks=[early_stopping_callback,checkpointer])
# 테스트 정확도를 출력합니다.print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, y_test)[1])) - 결국 일반 딥러닝의 과정 중 flatten 하기전에 multi dimension 형태로 convolusion 을 통해 일부만 추려내는 과정이 포함 된 것.
'TIL(2024y) > Deep learning' 카테고리의 다른 글
| 24.07.04-05 RNN (0) | 2024.07.08 |
|---|---|
| 24.07.08 Auto encoder (0) | 2024.07.08 |
| 24.07.01 Deep learning (구조 및 역할) (0) | 2024.07.01 |
| 24.06.12 Review(Decision Tree/ Random Tree) (1) | 2024.06.12 |
| 24.05.30 SLP/ MLP (0) | 2024.05.30 |



