Today's study
- 통계
- scaling
- Data split (test/ train data로 나누기)
통계적 수치 이해하기
- 분산/ 표준편차
- 표본에 대한 표준편차의 경우 분산에 n이 아닌 n-1을 나눠준다 (자유도)
- (모집단의 표준편차는 분산에 n을 나눠줌)
- correlation(상관계수)
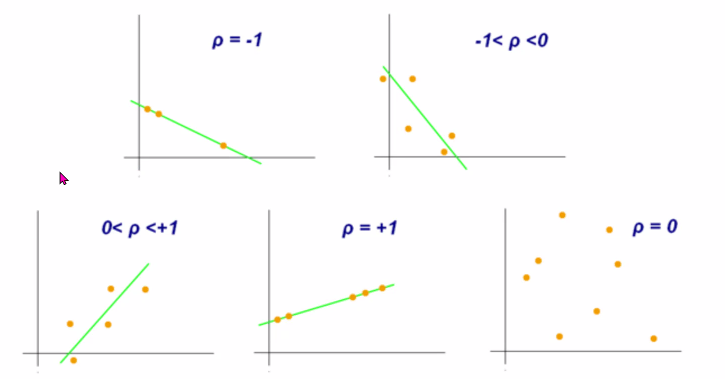
- 두 변수의 관계를 수치화 한 것
- 상관계수는 -1과 1사이의 값을 가짐
- 1이면 양의 관계/ -1이면 음의 관계
- 0에 가까울 수록 선형적인 관계가 아님
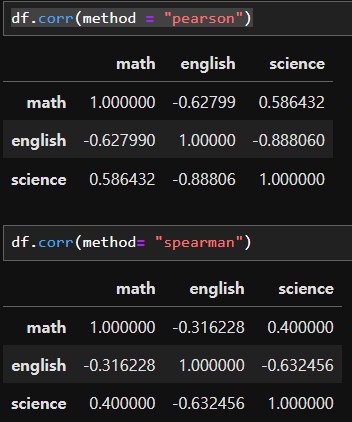
- numerical(수치) 데이터는 --> Pearson 상관계수 (일반적으로 상관관계 봤어? 하면 이것!)
numerial or categorical 데이터는 --> Spearman 상관계수로 두 데이터 관계를 구할 수 있음 - df.corr()에서 shift+tap 누르고 보면 method = Pearson 로 디폴트 지정되어있는 것을 볼 수 있음
- Pearson 상관계수의 해석 (기울기를 반영한 것이 아닌 상관관계만 반영)
- +/- 0.7 이상일 때 두 data 사이에 상관관계가 높다고 해석
- Spearman
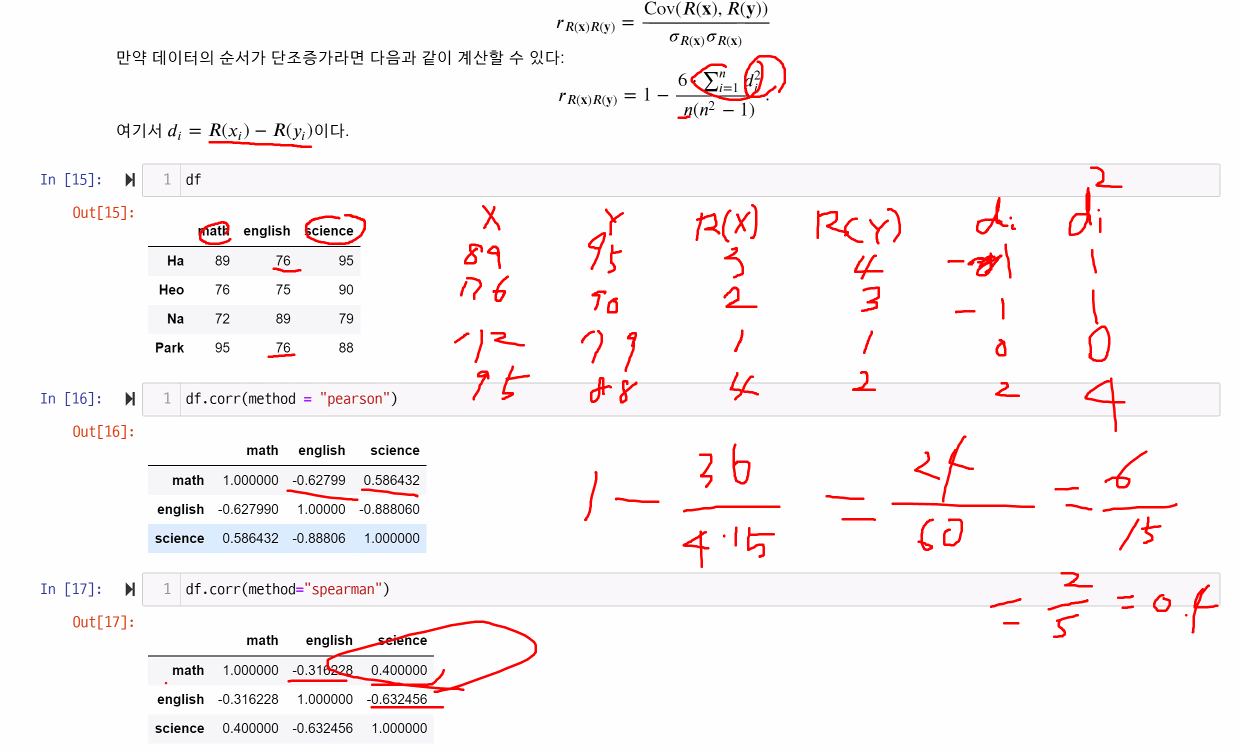
--> data를 rank했을 때의 차이 정도
- summary
- pearson 값 : data간 차이의 정도
- spearman 값: 각 data를 rank했을 때 그 차이의 정도
- e.g.
Scaling(스케일링)
- 스케일링이 필요한 이유
- 수치의 크기에 영향을 받는 모델은 특성의 데이터 분포 범위가 다를 경우 수치가 큰 특성에 영향을 많이 받을 수 밖에 없다
- 딥러닝 모델의 경우 스케일링이 반드시 필요
- 머신러닝 모델 중에도 스케일링이 필요한 것이 있음
- 스케일링의 종류
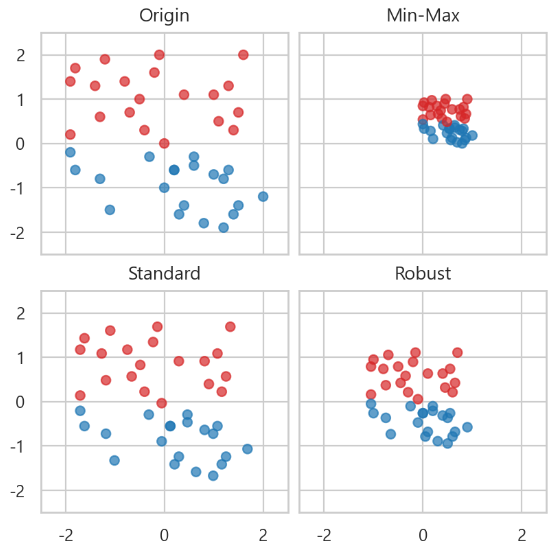
- Min-max scaling
- 스케일링한 값이 0 - 1 사이에 옴
- 이상치에 민감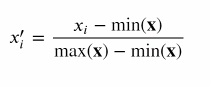
- Standard scaling
- scaling한 뒤 데이터가 정규분포를 따름
- 평균과 표준편차가 이상치에 영향을 받기에 이상치에 민감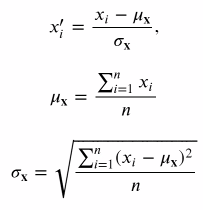
- Robust scaling
- 이상치에 덜 민감
- 중앙값이 0, IQR이 1로 변환
- Min-max scaling
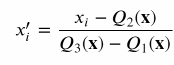
- 스케일링 시각화

- sklearn 설치: pip install scikit-learn
- e.g. df가 아래와 같은 분포를 가질 때
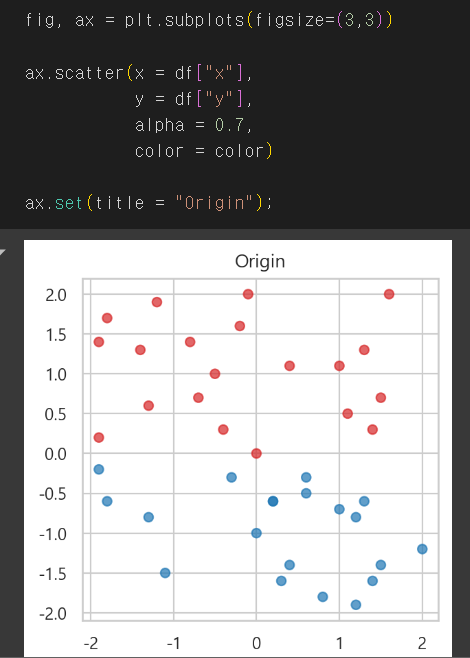
- Min-Max scaling
- 스케일링한 값이 0~1사이에 오게 됨
- minmax = MinMaxScaler() 사용
- df_min_max =minmax.filt_stransform(df[["x", "y"]]) - Standard scaling
- 스케일링한 후 데이터가 정규분표를 따름
- std = StandardScaler() 사용
- df_std=std.filt_stransform(df[["x", "y"]]) - Robust scaling
- 중앙값이 0, IQR이 1로 변환
- rob= RobustorScaler()
- df_rob =rob.filt_stransform(df[["x", "y"]]) - 네개의 스케일링을 비교
- Min-Max scaling
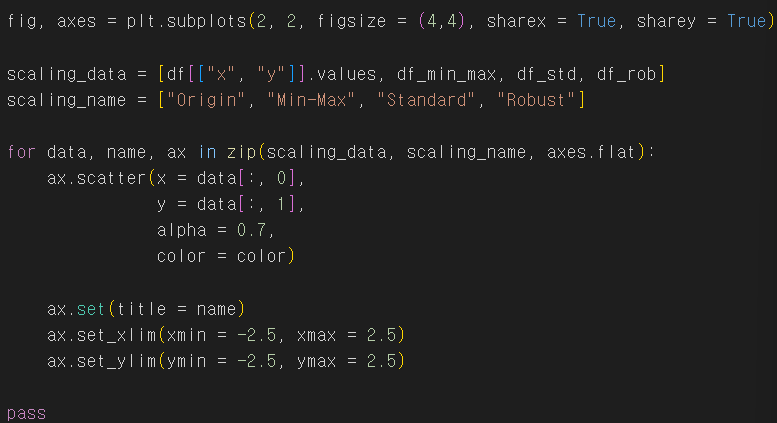
라이브러리 및 데이터 불러오기
- 차원의 축소
- 데이터의 특성이 많아지면 선형 모델은 학습 데이터에서 정확도가 높아지지만 과적합되기 쉬움
- 차원 축소는 데이터를 가장 잘 표현하는 특성을 선택하여 데이터의 크기를 줄이고 모델의 성능을 향상 시킬 수 있음
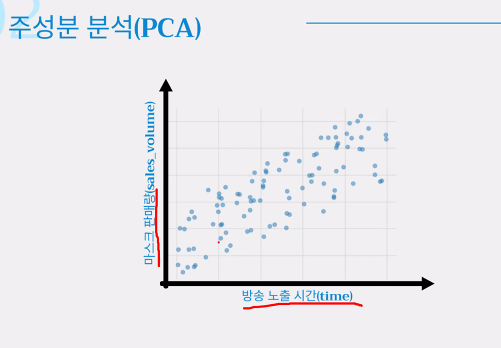
- 차원 축소의 대표적인 방법: 주성분 분석(principal component analysis, PCA)
- 주성분 분석은 비지도 학습에 해당
- PCA
- 데이터를 가장 잘 표현하는 벡터를 찾자
- 분산(데이터가 퍼져있는 정도)이 가장 큰 방향을 찾자 -> 이 방향 벡터가 데이터를 가장 잘 대변하는 것
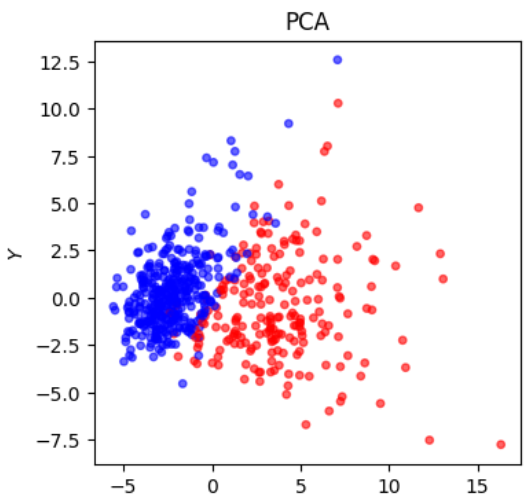
- Cancer data로 PCA 그리기
- cancer_pca = PCA(n_components =2).fit_transform(cancer_scaling)
Split (test/train data로 나누기)
- 알고리즘을 이용하여 모델을 만들기위해 위의 data 전체에서 75%로 training, 25%로 모델을 검증하기 위한 test 를 할 예정
- 그 다음, 해당 train/test data를 각각 1이 되도록 scaling 하기
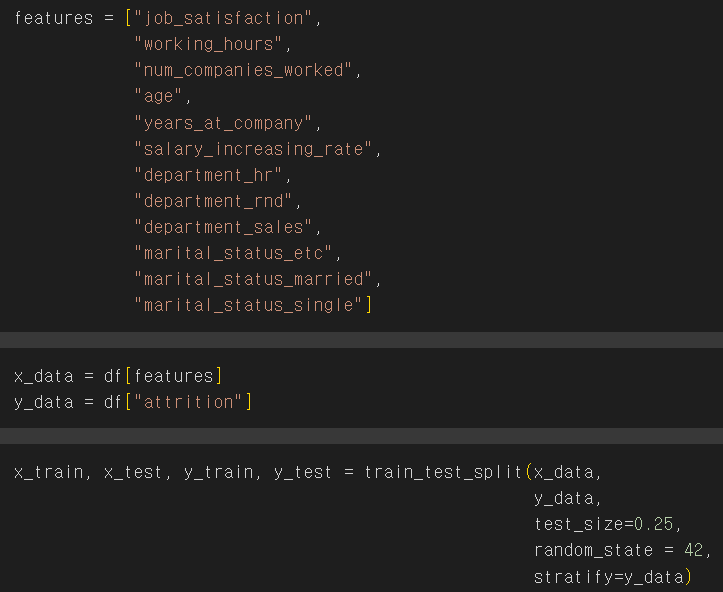
- HR data에서 attrition의 이유를 파악하고 싶다는 것을 목표로 세움
- 아래 attrition에 영향을 준다고 생각되는 features를 선택하여 x값으로 두고
- y값을 atrrition으로 설정
- test_size: test data는 전체에서 25% 쓰겠다
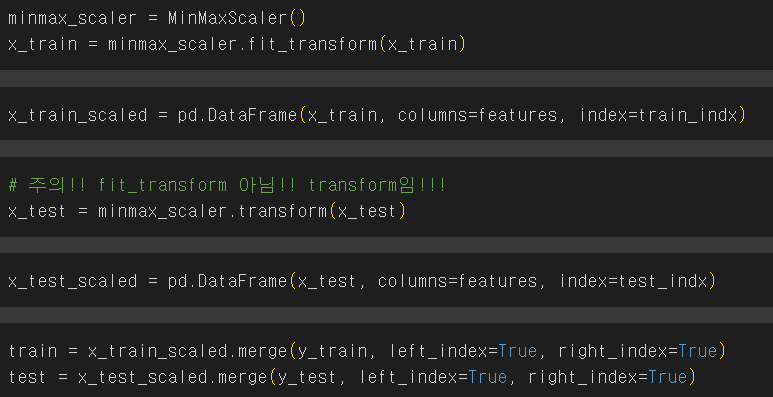
- test/train data를 scaling 해주기
- train = minmax_scaler.fit_transform(x_train)
- test = minmax_scaler.transform(x_test) - fit_transform:
- 데이터를 학습(fit)하고 변환(transform)하는 과정이 한 번에 이루어짐
- 학습(fit) 단계에서는 데이터의 최소값과 최대값을 계산하여 내부 상태를 설정
- 변환(transform) 단계에서는 계산된 최소값과 최대값을 사용하여 데이터를 스케일링
- 즉, fit_transform은 데이터를 처음 스케일링할 때 사용 - transform:
- 이미 학습된(fit) 상태를 사용하여 새로운 데이터를 변환(transform)
- 다시 학습하지 않고, 기존에 설정된 최소값과 최대값을 사용하여 데이터를 스케일링
- 따라서 transform은 학습된 스케일러를 사용하여 테스트 데이터를 스케일링할 때 주로 사용
[24.05.20 ~ 24.05.24 study]

'TIL(2024y) > Machine learning' 카테고리의 다른 글
| 24.06.10 Review (Summary/ Linear Regression with Pytorch) (0) | 2024.06.11 |
|---|---|
| 24.05.28 Ensemble model (Bagging/ Random tree) (0) | 2024.05.28 |
| 24.05.27 알고리즘 개념(Decision Tree) (0) | 2024.05.28 |
| 24.05.23 데이터 시각화 (0) | 2024.05.23 |
| 24.05.22 머신러닝 개념 및 이상치/결측치 해결 (0) | 2024.05.22 |



