Today's study
- Machine learing 개념
- Machince learining 모델링 과정 (데이터 준비)
1) 데이터전처리
- 결측치 해결하기 (Null 값 제거 등)
- 이상치 해결하기 (튀는 값 제거 등)
.
.
.
Maching learning 작업순서
1. 문제정의
- 머신러닝으로 풀 수 있는 문제가 맞는지 확인
- 분류/ 회귀/ 예측/ 이상값감지/ 그룹화/ 강화학습 중 어디 속하는지 확인
2. 데이터 준비
- 데이터 수집/ 데이터 전처리/ 데이터 추가
3. 알고리즘 선택
4. 모델학습
5. 모델 평가
- 언더피팅/ 오버피팅/ 모델 용량/ 평가지표
Data type
- Categorical data
- Nominal data
- 비교(equality)
- 최빈값 - Ordinal data
- 비교
- 최빈값
- 순서정렬
- 중앙값
- Nominal data
- Numeric data
- Interval data
- 비교
- 최빈값
- 순서정렬
- 중앙값
- 평균값
- 덧셈/뺄셈 - Radio data
- 비교
- 최빈값
- 순서정렬
- 중앙값
- 평균값
- 덧셈/뺄셈
- 곱셈/나눗셈
- Interval data
- Cetegorical data -> numeric data로 변환은 거의 힘듬 --> 처음 data 수집시 잘 판단해야함
결측치 해결하기
(HR 자료로 분석해 보기)
1. 결측값 확인하기
1) 시각적으로 확인하는 방법
- import missingono as msno # 데이터셋의 결측 데이터를 탐색적으로 시각화하는 Python 라이브러리
- msno.matrix(df);

- marital_status, num_companies_worked에서 NaN 값이 있는 것을 확인
2) 숫자로 확인하는 방법
- df[df["marital_status"].isnull()] 를 통해서 NaN값만 뽑아보기(시각화 or 값을 뽑아서 확인할 수 있음)
- len(df[df["marital_status"].isnull()]): df내 material_status열의 개수(길이) 알려주는 method
- 평균, 중앙값 입력하기
- 평균: np.mean() / df[ ].mean()
- 중앙값: np.median()/ df.[ ].media() - 결측을 median으로 채우기

- df['원하는 index'] = df['index'].fillna(df['index'].median()
- categorical
- ordinal: 순서가 있음
- norminal: 순서가 없음
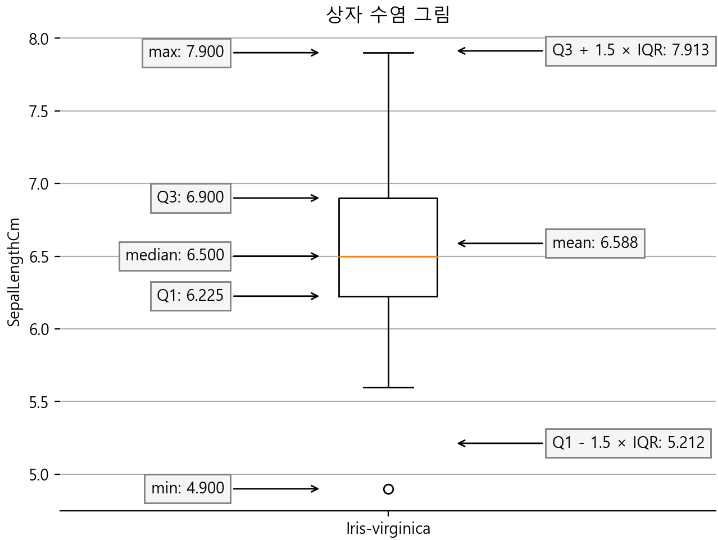
2. 이상치 해결하기
1) 튀는 값들이 있는지 확인하기
- working_hours, salary, last_year_salary, num_companies_worked 에 대해 boxplot을 그려보기

- boxplot
- 데이터의 분포를 시각적으로 표현하는 통계 그래프
- 주로 데이터의 분포, 중심 경향, 산포 및 이상값을 파악하는 데 사용
- 상자(Box): 데이터의 중간 50%를 포함하는 구간. 상자의 아래쪽 끝은 1사분위수(Q1), 위쪽 끝은 3사분위수(Q3) - 중앙값(Median): 상자의 중앙에 있는 선으로, 데이터의 중앙값을 나타냅니다.
- 수염(Whisker): 상자 양쪽 끝에서 데이터의 최솟값과 최댓값을 연결하는 선.
일반적으로 Q1 - 1.5 * IQR 이하의 값과 Q3 + 1.5 * IQR 이상의 값을 제외한 범위를 나타냄. 여기서 IQR은 Q3 - Q1. - 이상값(Outliers): 수염 밖에 있는 데이터 점들로, 주로 작은 점으로 표시됨.

- fig, ax = plt.subplots(figsize=(10,4)):
--> 가로 10, 세로4 인치 크기의 그림과 축을 생성 - ax.boxplot([df["working_hours"], df["salary"], df["last_year_salary"], df["num_companies_worked"]]):
--> df의 네 개 열(working_hours, salary, last_year_salary, num_companies_worked)에 대한 박스플롯을 그림 - ax.set_xticklabels(["working_hours", "salary", "last_year_salary", "num_companies_worked"]):
--> x축 레이블을 각각 "working_hours", "salary", "last_year_salary", "num_companies_worked"로 설정 - 급여가 top에 있는 samples 뽑기

- df[ ].sort_values(ascending=False)
- salary 열만 내림차순으로 정렬하여 시리즈(Series) 형태로 반환
- Table로 나타내기

- salary 열을 내림차순으로 정렬한 후, 해당 정렬된 인덱스를 사용하여 원래 데이터프레임 df의 모든 열을 반환
- 즉, salary 열을 기준으로 데이터프레임 전체를 정렬한 결과를 얻음
2) IQR 을 이용하여 이상 값(튀는 값) 확인하기
- +/- 1.5 * Inter quartile range(IQR) 값인지 확인하기
3) 튀는 값 drop 시키기
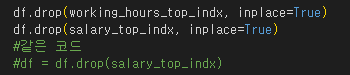
- Pandas 데이터프레임 df에서 특정 행을 삭제하는 명령
- inplace=Treu
- 삭제 작업이 원본 데이터프레임에 직접 적용된다는 의미.
- 새로운 데이터프레임을 반환하지 않고 원본 데이터프레임이 수정됨
- df.drop('index')도 같은 코드
데이터 타입 변경과 특성 생성하기
- e.g. HR자료에서 raw data보다 분석에 적합한 data로 변경
- One-hot encoding
- 비어있는 칸/ 행렬이 맞지 않는 칸들을 0으로 채워주기
'TIL > Machine learning' 카테고리의 다른 글
| 24.06.10 Review (Summary/ Linear Regression with Pytorch) (0) | 2024.06.11 |
|---|---|
| 24.05.28 Ensemble model (Bagging/ Random tree) (0) | 2024.05.28 |
| 24.05.27 알고리즘 개념(Decision Tree) (0) | 2024.05.28 |
| 24.05.24 통계 / scaling / data split (0) | 2024.05.26 |
| 24.05.23 데이터 시각화 (0) | 2024.05.23 |



