Cross validation
- stratifiedKFold()
Grid Search
- model parameter: 일반적인 parameter 의미. 모델이 학습하면서 변화하게되는 값. 딥러닝 모델의 경우 가중치가 파라미터
- 하이퍼 parameter: 매개변수. 모델의 학습 전에 설정해 주는 값. 아무런 설정도 하지않으면 기본값(default)로 학습하게 됨
Ensemble Learning (앙상블 model)
1. Bagging(Bootstrapp Aggregating)
- Each member of the ensemble is constructed from a different training dataset
- Each dataset is generated by sampling from the total N data examples, choosing N items uniformly at random with replacement (동일한 data에서 부분집합으로 계속 dataset을 만듬, 한번 뽑았던 것도 포함해서)
- Each dataset sample is known as a bootstrap
- e.g. 1~100 -> 10개씩 계속 뽑아냄
- Probability that an instance is not included in a bootstrap
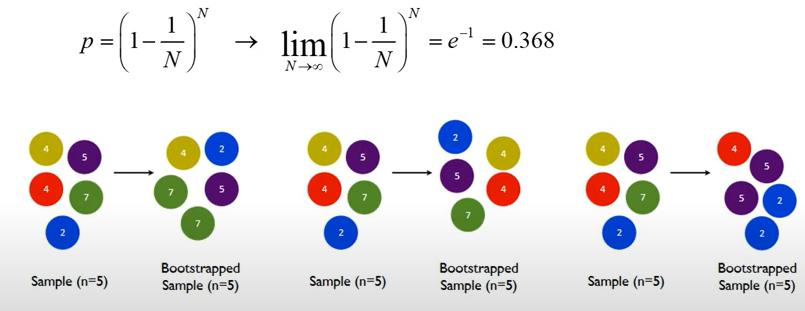
- 한번도 안뽑힐 확률 = p
- 무한대로 반복해주면 p = 0.368
- 즉, N이 일정 수준 이상으로 큰 수이면
- 2/3은 Bootstrap에 1회이상 샘플로 포함된다
- 1/3은 Boostrap에 0회 샘플링 됨 = Out of bay(OOB) --> 사용되지 않은 oob로 검증에 사용
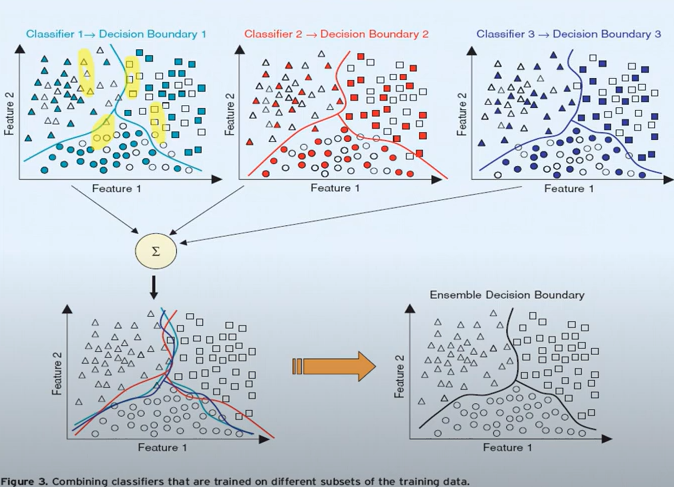
- Combining clssifiers that are tranied on different subsets of the training data
2. Random Forests
- Bagging 의 한 종류
- Randomly chosen predictor variables, 여러 알고리즘을 섞어서(모아서) 예측하는 방법
- Decision Tree가 모여 만든 앙상블 모델
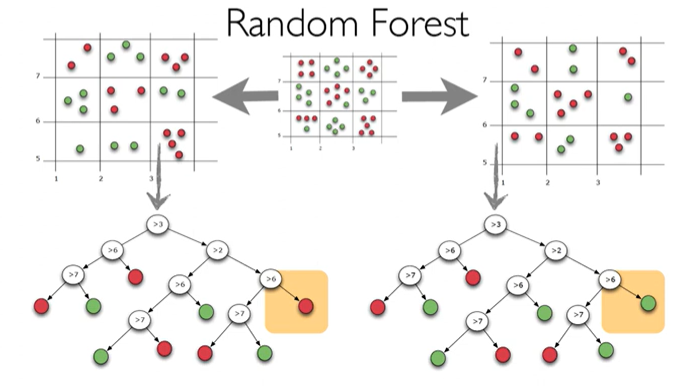
- Decision tree를 base로 한 bagging algorism
- Traning data/ oob 로 나눠서 DT
- 각각의 Boostrap data에 대해서(복원추출로 다양성을 한번 확보한 것에서) DT 진행( 그냥 DT하는 것과 달리 dataset을 만들어서 그 dataset에 대해 다시 DT를 진행?)
--> Dataset이 많아서 accuracy가 높아짐 ? 개념인듯.. - Features의 중요도(오 굿!)

- OOB error의 평균값이 높고, 표준편차가 적을 수록 해당 변수의 중요도가 높다는 뜻
- Random Forest Classifier 용어
- n_estimators: Decision Tree의 개수
- max_features: feature을 랜덤하게 몇 개를 뽑을 것인가
- oob_score_:
- bootstrap: False로 누락했을 경우 oob_score_를 계산하지 않음
- verbose: 학습하는 동안 정보출력
- class_weight: 클래스에 dict 형태로 가중치를 줄 수도있음
- max_samples: 샘플을 몇 개 뽑을 것인가. 기본적으로 boostrap을 sampling할 때 training data의 size만큼 뽑지만 지정도 가능
- max_depth: Decision tree의 최대 깊이
- DT나 RFC 모델의 하이퍼 parameter은 너무 많아서 아래 parameter 정도를 조정해 주면 좋음
- max_depth
- max_features
- min_samples_leaf
- max_leaf_nodes
- min_samples_split
- 일반적으로 max 이름을 가진 하이퍼 parameter는 감소/ min은 증가시키면 모델의 성능이 향상된다고 함
- Cancer data를 이용하여 Ensemble Random Forests
- OOB_score 확인하기
- 다양한 n_estimators 값에 따른 모델의 성능을 확인
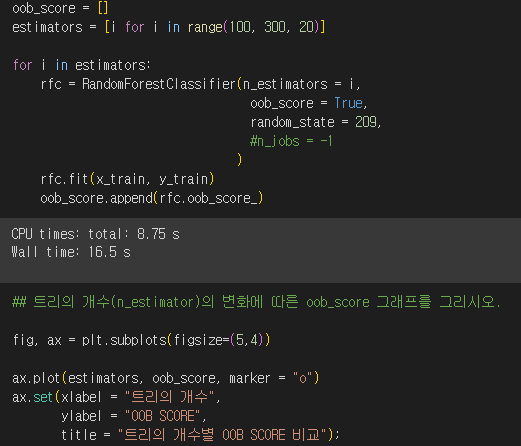
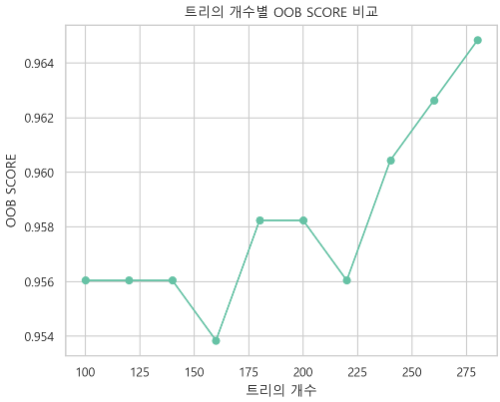
- estimators의 리스트 생성하고, 이 리스트는 100에서 300까지 20씩 증가하는 값을 가짐.
- oob_score 빈 리스트를 생성: 각 모델에 대한 OOB 값 저장할 것
- Feature importance 확인하기
- RandomForestClassifier에서 각 특성(feature)의 중요도(importance)를 나타내는 속성(attribute)cancer_rfc.feature_importances_
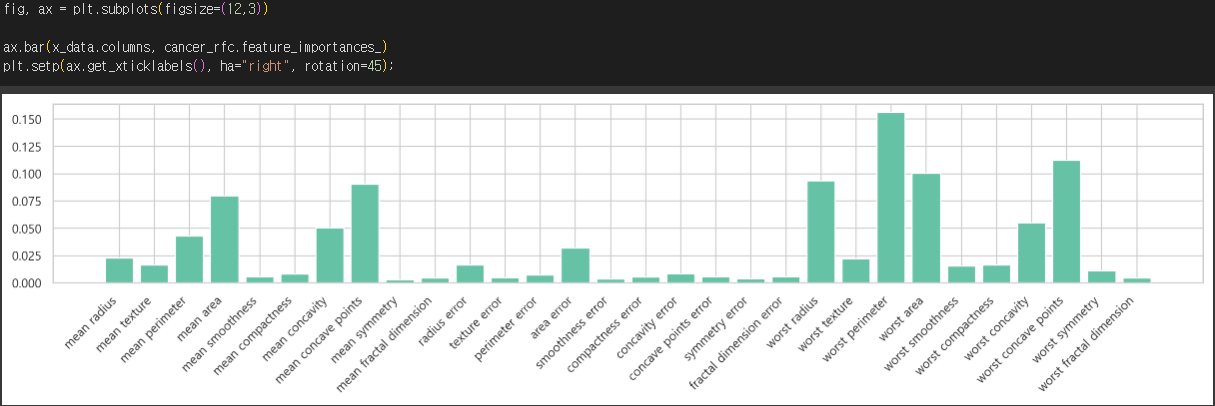
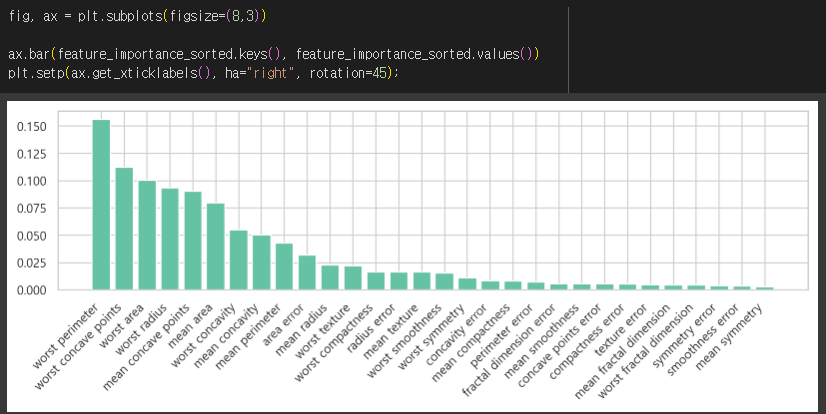
- feature_importance_sorted 딕셔너리를 생성
- feature_importance 딕셔너리를 중요도에 따라 내림차순으로 정렬하여 저장
- 이를 위해 sorted 함수를 사용하고, key 매개변수를 사용하여 중요도를 기준으로 정렬
- reverse 매개변수를 사용하여 내림차순으로 정렬
'TIL(2024y) > Machine learning' 카테고리의 다른 글
| 24.06.11 Review (Sampling/Preparation/K-NN/Model Evaluation) (1) | 2024.06.11 |
|---|---|
| 24.06.10 Review (Summary/ Linear Regression with Pytorch) (0) | 2024.06.11 |
| 24.05.27 알고리즘 개념(Decision Tree) (0) | 2024.05.28 |
| 24.05.24 통계 / scaling / data split (0) | 2024.05.26 |
| 24.05.23 데이터 시각화 (0) | 2024.05.23 |



