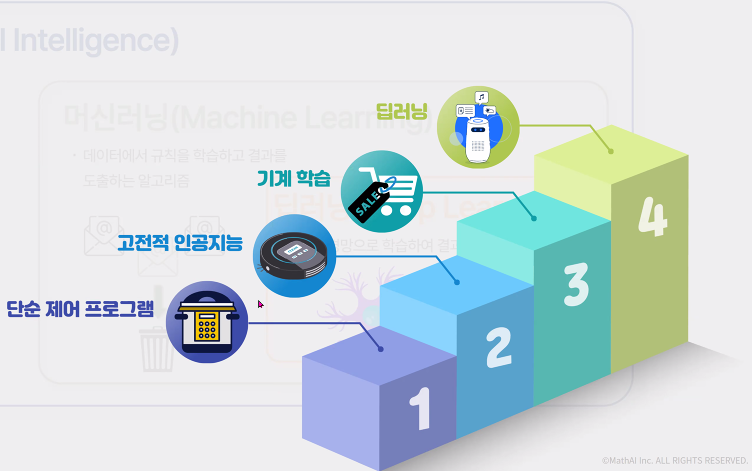
지도학습은 정답이 있어야 학습이 가능함 - 회귀 e.g. 부동산/도시가스 비용 예측 - 주로 우리 주변(2024y)은 지도학습 위주로 구성되어있음
비지도학습
- 정답은 없고 비슷한 것끼리 분류
강화학습 - 벽돌깨기, 바둑 등 y/n 로 분류해서 y로가면 점수를 가하도록해서 학습을 시킨 것 --> 벽돌깨기의 경우 약 4시간 학습 후 빨리 레벨업 점수에 도달하도록 학습 됨
데이터
데이터 종류
- 대부분 정형데이터
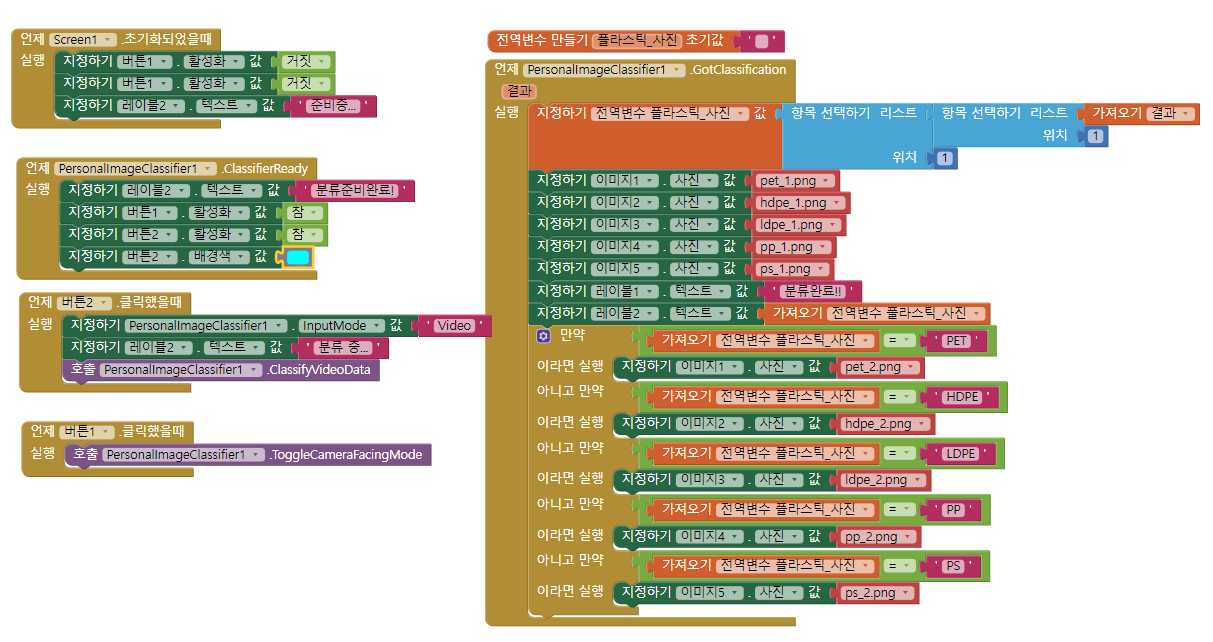
Plastic 분류하는 앱 만들기 실습
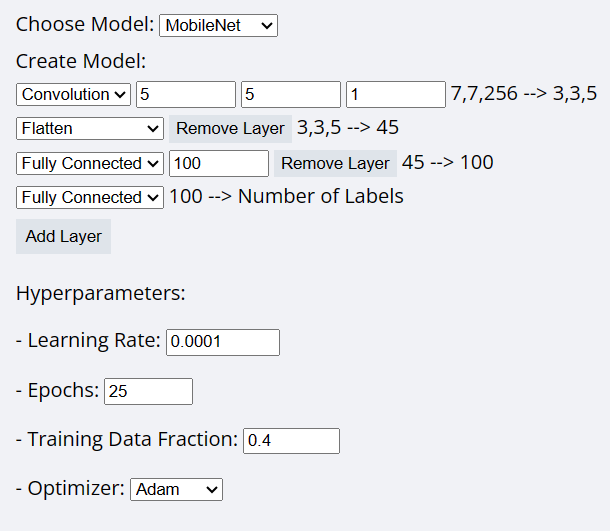
mdl 파일 만들기
- Epochs: data가 한번 학습하는 단위 e.g. Epochs:20 = data를 20번 학습한다 - Learning rate: 정답에 가까워져가는 보폭? --> 너무 작으면 시간이 오래걸리고, 빠르면 정답을 지나쳐버릴 수도 있음 - Optimizer: 출력 data가 정답과 얼마나 거리가 있는지 측정하는 함수 (Adam을 많이 씀) - Training Data Fraction: 모델의 성능을 평가하는 validation 수치 (기준이 되는 test data는 사용할 수 없기에)
json.load( ) - 열린 파일에서 JSON 데이터를 읽어들임 - 이 함수는 JSON 파일의 내용을 파이썬의 딕셔너리나 리스트와 같은 데이터 구조로 변환함 - JSON 파일은 텍스트 기반의 데이터 교환 형식으로, 파이썬의 데이터 구조와 매우 유사 - 그래서 JSON 데이터를 읽어들여 파이썬에서 활용하기 용이하도록 변환하는 것
open(geo_path, encoding="utf-8") - geo_path 변수에 저장된 경로에 있는 파일을 여는 것 - encoding="utf-8"은 파일이 UTF-8 인코딩으로 되어있다는 것을 명시함. UTF-8은 유니코드 문자를 효과적으로 처리하기 위한 표준 인코딩 방식 중 하나
folium -folium은 파이썬의 지리정보 시각화를 위한 라이브러리 중 하나 - 주로 지리적 데이터를 지도 위에 시각화할 때 사용
folium.Choropleth( ) 함수 1) 형식 : folium.Choropleth( )는 다양한 패러미터를 받아들여 지도를 시각함. 2) 주요 parameter - geo_data: GeoJSON 형식의 지리 데이터를 포함하는 파일 또는 URL - name: 레이어의 이름 - data: 단계 구분도에 사용될 데이터 프레임. - columns: 데이터 프레임에서 사용할 열 이름 (예: ['지역', '값']) - key_on: GeoJSON 파일에서 데이터를 매칭하기 위한 키 (예: 'feature.id'). - fill_color: 단계 구분도의 색상 맵 (예: 'YlGn', 'BuPu', 'Reds', etc.) - fill_opacity: 단계 구분도의 투명도 (0에서 1 사이의 값) - line_opacity: 경계선의 투명도 (0에서 1 사이의 값) - legend_name: 범례의 이름 - highlight: 지역을 강조할지 여부
choropleth(단계구분도): 색상이나 패턴을 사용하여 특정 통계에 대한 데이터를 사전 정의된 영역과 관련시켜 시각화 한 지도 유형
fill_color: 색상정보
key_on: 지리정보와 시각화정보의 공통변수로서 'feature.id'를 설정
legend_name: colorbar아래 적어줄 문구
부산 지도에서 특정 data 시각화하기
부산 정보가 들어있는 json file에서 구 이름 출력하기
- 복잡한 자료를 json.load( )를 이용하여 dictrionary/list 구조로 변환 - key()를 이용하여 key, values를 확인 - 그 결과 features가 values 값인 것을 확인 함 --> "구"인 values 값을 불러오기위해 해당 key인 id를 입력
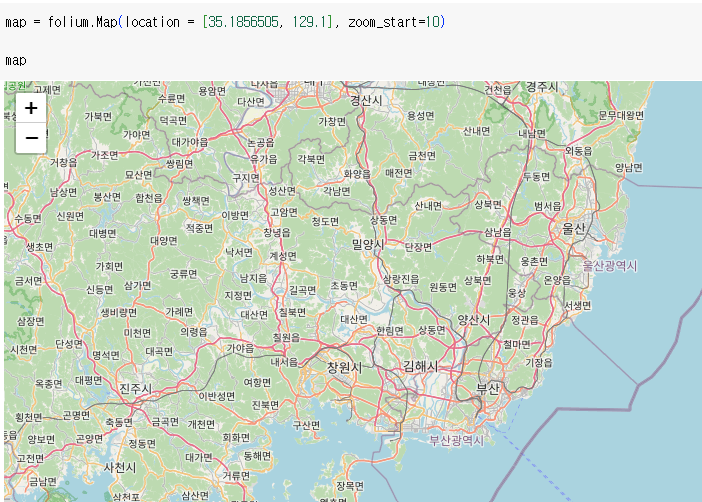
부산 지도 시각화
- folium.Map(location = [부산의 위도, 경도값 입력 - 부산지도 검색 후 link에 정보 有)] , zoom_start=초기 확대 수준
부산지도에서 인수구 별로 color 표시하기
- geo_data = 부산정보를 보겠다 - data: dataframe에서 population 열을 보겠다 - full_ color는 red로 하겠다 - key_on: Json data와 population의 data를 mapping(연결시키는 것) 하기 위한 key로 Json의 id와 df의 index를 일치
시킴. e.g. Json file에 부산의 각 구의 id가 1, 2, 3 등으로 되어있고 dataframe에도 동안한 id로 인구수 정보가 있다면
이 key 를 이용하여 지도와 data를 연결시킴 - legend_name: 지도의 범례에 표시될 텍스트로 각 구역의 색상이 나타내는 데이터가 무엇인지 설명
부산 집값의 평균을 시각화하기
QUIZ
name_eng를 수집하여 df에 "gu_eng"의 열을 만드시오.
부산 구별 인구밀도를 계산하여 df에 "density"열을 추가하고, 인구밀도 값을 추가하시오.